
Deployment
Business archives
To deploy processes, they have to be wrapped in a business archive (BAR). A business archive is the unit of deployment to a Flowable engine. A business archive is equivalent to a ZIP file. It can contain BPMN 2.0 processes, form definitions, DMN rules and any other type of file. In general, a business archive contains a collection of named resources.
When a business archive is deployed, it is scanned for BPMN files with a .bpmn20.xml or .bpmn extension. Each of those will be processed and may contain multiple process definitions. When the DMN engine is activated, .dmn files are also parsed, and with the form engine activated, .form files are handled.
Note
Java classes present in the business archive will not be added to the classpath. All custom classes used in process definitions in the business archive (for example, Java service tasks or event listener implementations) must be made available on the Flowable engine classpath in order to run the processes.
Deploying programmatically
Deploying a business archive from a ZIP file can be done like this:
String barFileName = "path/to/process-one.bar";
ZipInputStream inputStream = new ZipInputStream(new FileInputStream(barFileName));
repositoryService.createDeployment()
.name("process-one.bar")
.addZipInputStream(inputStream)
.deploy();
It’s also possible to build a deployment from individual resources. See the javadocs for more details.
External resources
Process definitions live in the Flowable database. These process definitions can reference delegation classes when using Service Tasks or execution listeners or Spring beans from the Flowable configuration file. These classes and the Spring configuration file have to be available to all process engines that may execute the process definitions.
Java classes
All custom classes that are used in your process (for example, JavaDelegates used in Service Tasks or event-listeners, TaskListeners and so on) should be present on the engine’s classpath when an instance of the process is started.
During deployment of a business archive however, those classes don’t have to be present on the classpath. This means that your delegation classes don’t have to be on the classpath when deploying a new business archive with Ant, for example.
When you are using the demo setup and you want to add your custom classes, you should add a JAR containing your classes to the flowable-task or flowable-rest webapp lib. Don’t forget to include the dependencies of your custom classes (if any) as well. Alternatively, you can include your dependencies in the libraries directory of your Tomcat installation, ${tomcat.home}/lib.
Using Spring beans from a process
When expressions or scripts use Spring beans, those beans have to be available to the engine when executing the process definition. If you are building your own webapp and you configure your process engine in your context as described in the spring integration section, that is straightforward. But bear in mind that you also should update the Flowable task and rest webapps with that context if you use it.
Creating a single app
Instead of making sure that all process engines have all the delegation classes on their classpath and use the right Spring configuration, you may consider including the Flowable REST webapp inside your own webapp so that there is only a single ProcessEngine.
Versioning of process definitions
BPMN doesn’t have a notion of versioning. That is actually good, because the executable BPMN process file will probably live in a version control system repository (such as Subversion, Git or Mercurial) as part of your development project. However, versions of process definitions are created in the engine as part of deployment. During deployment, Flowable will assign a version to the ProcessDefinition before it is stored in the Flowable DB.
For each process definition in a business archive, the following steps are performed to initialize the properties key, version, name and id:
The process definition id attribute in the XML file is used as the process definition key property.
The process definition name attribute in the XML file is used as the process definition name property. If the name attribute is not specified, then the id attribute is used as the name.
The first time a process with a particular key is deployed, version 1 is assigned. For all subsequent deployments of process definitions with the same key, the version will be set 1 higher than the highest currently deployed version. The key property is used to distinguish process definitions.
The id property is set to {processDefinitionKey}:{processDefinitionVersion}:{generated-id}, where generated-id is a unique number added to guarantee uniqueness of the process ID for the process definition caches in a clustered environment.
Take for example the following process
<definitions id="myDefinitions" >
<process id="myProcess" name="My important process" >
...
When deploying this process definition, the process definition in the database will look like this:
| id | key | name | version |
|---|---|---|---|
myProcess:1:676 |
myProcess |
My important process |
1 |
Suppose we now deploy an updated version of the same process (for example, changing some user tasks), but the id of the process definition remains the same. The process definition table will now contain the following entries:
| id | key | name | version |
|---|---|---|---|
myProcess:1:676 |
myProcess |
My important process |
1 |
myProcess:2:870 |
myProcess |
My important process |
2 |
When the runtimeService.startProcessInstanceByKey("myProcess") is called, it will now use the process definition with version 2, as this is the latest version of the process definition.
Should we create a second process, as defined below and deploy this to Flowable, a third row will be added to the table.
<definitions id="myNewDefinitions" >
<process id="myNewProcess" name="My important process" >
...
The table will look like this:
| id | key | name | version |
|---|---|---|---|
myProcess:1:676 |
myProcess |
My important process |
1 |
myProcess:2:870 |
myProcess |
My important process |
2 |
myNewProcess:1:1033 |
myNewProcess |
My important process |
1 |
Note how the key for the new process is different from our first process. Even though the name is the same (we should probably have changed that too), Flowable only considers the id attribute when distinguishing processes. The new process is therefore deployed with version 1.
Providing a process diagram
A process diagram image can be added to a deployment. This image will be stored in the Flowable repository and is accessible through the API. This image is also used to visualize the process in Flowable apps.
Suppose we have a process on our classpath, org/flowable/expenseProcess.bpmn20.xml that has a process key 'expense'. The following naming conventions for the process diagram image apply (in this specific order):
If an image resource exists in the deployment that has a name of the BPMN 2.0 XML file name concatenated with the process key and an image suffix, this image is used. In our example, this would be org/flowable/expenseProcess.expense.png (or .jpg/gif). In case you have multiple images defined in one BPMN 2.0 XML file, this approach makes most sense. Each diagram image will then have the process key in its file name.
If no such image exists, am image resource in the deployment matching the name of the BPMN 2.0 XML file is searched for. In our example this would be org/flowable/expenseProcess.png. Note that this means that every process definition defined in the same BPMN 2.0 file has the same process diagram image. In case there is only one process definition in each BPMN 2.0 XML file, this is obviously not a problem.
Example when deploying programmatically:
repositoryService.createDeployment()
.name("expense-process.bar")
.addClasspathResource("org/flowable/expenseProcess.bpmn20.xml")
.addClasspathResource("org/flowable/expenseProcess.png")
.deploy();
The image resource can be retrieved through the API afterwards:
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.processDefinitionKey("expense")
.singleResult();
String diagramResourceName = processDefinition.getDiagramResourceName();
InputStream imageStream = repositoryService.getResourceAsStream(
processDefinition.getDeploymentId(), diagramResourceName);
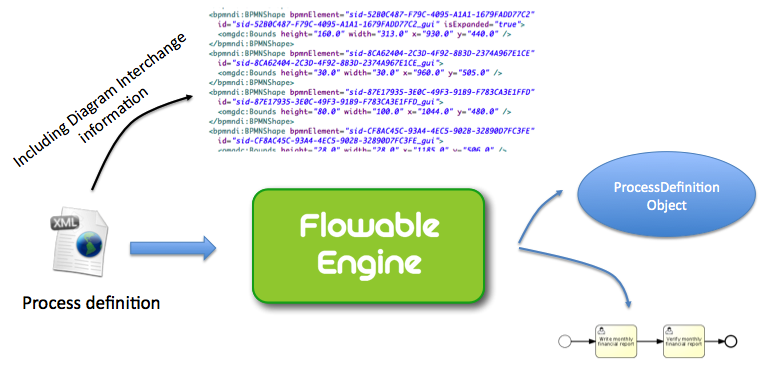
Generating a process diagram
If no image is provided in the deployment, as described in the previous section, the Flowable engine will generate a process diagram image if the process definition contains the necessary 'diagram interchange' information.
The resource can be retrieved in exactly the same way as when an image is provided in the deployment.
If, for some reason, it’s not necessary or desirable to generate a diagram during deployment, the isCreateDiagramOnDeploy property can be set on the process engine configuration:
<property name="createDiagramOnDeploy" value="false" />
No diagram will be generated now.
Category
Both deployments and process definitions have user-defined categories. The process definition category is initialized with the value of the targetNamespace attribute in the BPMN XML: <definitions ... targetNamespace="yourCategory" ...
The deployment category can also be specified in the API like this:
repositoryService
.createDeployment()
.category("yourCategory")
...
.deploy();