
The Flowable API
The Process Engine API and services
The engine API is the most common way of interacting with Flowable. The main starting point is the ProcessEngine, which can be created in several ways as described in the configuration section. From the ProcessEngine, you can obtain the various services that contain the workflow/BPM methods. ProcessEngine and the services objects are thread safe, so you can keep a reference to one of those for a whole server.
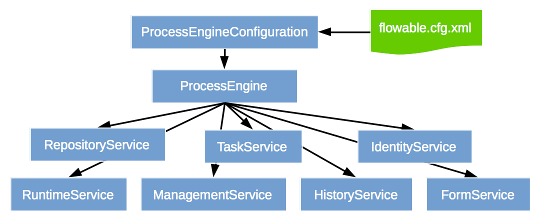
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();
RuntimeService runtimeService = processEngine.getRuntimeService();
RepositoryService repositoryService = processEngine.getRepositoryService();
TaskService taskService = processEngine.getTaskService();
ManagementService managementService = processEngine.getManagementService();
IdentityService identityService = processEngine.getIdentityService();
HistoryService historyService = processEngine.getHistoryService();
FormService formService = processEngine.getFormService();
DynamicBpmnService dynamicBpmnService = processEngine.getDynamicBpmnService();
ProcessEngines.getDefaultProcessEngine() will initialize and build a process engine the first time it is called and afterwards always return the same process engine. Proper creation and closing of all process engines can be done with ProcessEngines.init() and ProcessEngines.destroy().
The ProcessEngines class will scan for all flowable.cfg.xml and flowable-context.xml files. For all flowable.cfg.xml files, the process engine will be built in the typical Flowable way: ProcessEngineConfiguration.createProcessEngineConfigurationFromInputStream(inputStream).buildProcessEngine(). For all flowable-context.xml files, the process engine will be built in the Spring way: first the Spring application context is created and then the process engine is obtained from that application context.
All services are stateless. This means that you can easily run Flowable on multiple nodes in a cluster, each going to the same database, without having to worry about which machine actually executed previous calls. Any call to any service is idempotent regardless of where it is executed.
The RepositoryService is probably the first service needed when working with the Flowable engine. This service offers operations for managing and manipulating deployments and process definitions. Without going into much detail here, a process definition is a Java counterpart of the BPMN 2.0 process. It is a representation of the structure and behavior of each of the steps of a process. A deployment is the unit of packaging within the Flowable engine. A deployment can contain multiple BPMN 2.0 XML files and any other resource. The choice of what is included in one deployment is up to the developer. It can range from a single process BPMN 2.0 XML file to a whole package of processes and relevant resources (for example, the deployment 'hr-processes' could contain everything related to HR processes). The RepositoryService can deploy such packages. Deploying a deployment means it is uploaded to the engine, where all processes are inspected and parsed before being stored in the database. From that point on, the deployment is known to the system and any process included in the deployment can now be started.
Furthermore, this service allows you to:
Query on deployments and process definitions known to the engine.
Suspend and activate deployments as a whole or specific process definitions. Suspending means no further operations can be performed on them, while activation is the opposite and enables operations again.
Retrieve various resources, such as files contained within the deployment or process diagrams that were auto-generated by the engine.
Retrieve a POJO version of the process definition, which can be used to introspect the process using Java rather than XML.
While the RepositoryService is mostly about static information (data that doesn’t change, or at least not a lot), the RuntimeService is quite the opposite. It deals with starting new process instances of process definitions. As said above, a process definition defines the structure and behavior of the different steps in a process. A process instance is one execution of such a process definition. For each process definition there typically are many instances running at the same time. The RuntimeService also is the service that is used to retrieve and store process variables. This is data that is specific to the given process instance and can be used by various constructs in the process (for example, an exclusive gateway often uses process variables to determine which path is chosen to continue the process). The Runtimeservice also allows you to query on process instances and executions. Executions are a representation of the 'token' concept of BPMN 2.0. Basically, an execution is a pointer to where the process instance currently is. Lastly, the RuntimeService is used whenever a process instance is waiting for an external trigger and the process needs to be continued. A process instance can have various wait states and this service contains various operations to 'signal' to the instance that the external trigger is received and the process instance can be continued.
Tasks that need to be performed by human users of the system are core to a BPM engine such as Flowable. Everything around tasks is grouped in the TaskService, such as:
Querying tasks assigned to users or groups
Creating new standalone tasks. These are tasks that are not related to a process instance.
Manipulating to which user a task is assigned or which users are in some way involved with the task.
Claiming and completing a task. Claiming means that someone decided to be the assignee for the task, meaning that this user will complete the task. Completing means 'doing the work of the tasks'. Typically this is filling in a form of sorts.
The IdentityService is pretty simple. It supports the management (creation, update, deletion, querying, …) of groups and users. It is important to understand that Flowable actually doesn’t do any checking on users at runtime. For example, a task could be assigned to any user, but the engine doesn’t verify whether that user is known to the system. This is because the Flowable engine can also be used in conjunction with services such as LDAP, Active Directory, and so on.
The FormService is an optional service. Meaning that Flowable can be used quite happily without it, without sacrificing any functionality. This service introduces the concept of a start form and a task form. A start form is a form that is shown to the user before the process instance is started, while a task form is the form that is displayed when a user wants to complete a form. Flowable allows the specification of these forms in the BPMN 2.0 process definition. This service exposes this data in an easy way to work with. But again, this is optional, as forms don’t need to be embedded in the process definition.
The HistoryService exposes all historical data gathered by the Flowable engine. When executing processes, a lot of data can be kept by the engine (this is configurable), such as process instance start times, who did which tasks, how long it took to complete the tasks, which path was followed in each process instance, and so on. This service exposes mainly query capabilities to access this data.
The ManagementService is typically not needed when coding custom application using Flowable. It allows the retrieval of information about the database tables and table metadata. Furthermore, it exposes query capabilities and management operations for jobs. Jobs are used in Flowable for various things, such as timers, asynchronous continuations, delayed suspension/activation, and so on. Later on, these topics will be discussed in more detail.
The DynamicBpmnService can be used to change part of the process definition without needing to redeploy it. You can, for example, change the assignee definition for a user task in a process definition, or change the class name of a service task.
For more detailed information on the service operations and the engine API, see the javadocs.
Exception strategy
The base exception in Flowable is the org.flowable.engine.FlowableException, an unchecked exception. This exception can be thrown at all times by the API, but 'expected' exceptions that happen in specific methods are documented in the javadocs. For example, an extract from TaskService:
/**
* Called when the task is successfully executed.
* @param taskId the id of the task to complete, cannot be null.
* @throws FlowableObjectNotFoundException when no task exists with the given id.
*/
void complete(String taskId);
In the example above, when an id is passed for which no task exists, an exception will be thrown. Also, since the javadoc explicitly states that taskId cannot be null, an FlowableIllegalArgumentException will be thrown when null is passed.
Even though we want to avoid a big exception hierarchy, the following subclasses are thrown in specific cases. All other errors that occur during process-execution or API-invocation that don’t fit into the possible exceptions below, are thrown as regular FlowableExceptions.
FlowableWrongDbException: Thrown when the Flowable engine discovers a mismatch between the database schema version and the engine version.
FlowableOptimisticLockingException: Thrown when an optimistic locking occurs in the data store caused by concurrent access of the same data entry.
FlowableClassLoadingException: Thrown when a class requested to load was not found or when an error occurred while loading it (e.g. JavaDelegates, TaskListeners, …).
FlowableObjectNotFoundException: Thrown when an object that is requested or actioned does not exist.
FlowableIllegalArgumentException: An exception indicating that an illegal argument has been supplied in a Flowable API-call, an illegal value was configured in the engine’s configuration or an illegal value has been supplied or an illegal value is used in a process-definition.
FlowableTaskAlreadyClaimedException: Thrown when a task is already claimed, when the taskService.claim(...) is called.
Query API
There are two ways of querying data from the engine: the query API and native queries. The Query API allows you to program completely typesafe queries with a fluent API. You can add various conditions to your queries (all of which are applied together as a logical AND) and precisely one ordering. The following code shows an example:
List<Task> tasks = taskService.createTaskQuery()
.taskAssignee("kermit")
.processVariableValueEquals("orderId", "0815")
.orderByDueDate().asc()
.list();
Sometimes you need more powerful queries, for example, queries using an OR operator or restrictions you cannot express using the Query API. For these cases, we have native queries, which allow you to write your own SQL queries. The return type is defined by the Query object you use and the data is mapped into the correct objects (Task, ProcessInstance, Execution, …). Since the query will be fired at the database you have to use table and column names as they are defined in the database; this requires some knowledge about the internal data structure and it is recommended to use native queries with care. The table names can be retrieved through the API to keep the dependency as small as possible.
List<Task> tasks = taskService.createNativeTaskQuery()
.sql("SELECT * FROM " + managementService.getTableName(Task.class) +
" T WHERE T.NAME_ = #{taskName}")
.parameter("taskName", "gonzoTask")
.list();
long count = taskService.createNativeTaskQuery()
.sql("SELECT count(*) FROM " + managementService.getTableName(Task.class) + " T1, " +
managementService.getTableName(VariableInstanceEntity.class) + " V1 WHERE V1.TASK_ID_ = T1.ID_")
.count();
Variables
Every process instance needs and uses data to execute the steps it’s made up of. In Flowable, this data is called variables, which are stored in the database. Variables can be used in expressions (for example, to select the correct outgoing sequence flow in an exclusive gateway), in Java service tasks when calling external services (for example to provide the input or store the result of the service call), and so on.
A process instance can have variables (called process variables), but also executions (which are specific pointers to where the process is active) and user tasks can have variables. A process instance can have any number of variables. Each variable is stored in a row in the ACT_RU_VARIABLE database table.
All of the startProcessInstanceXXX methods have an optional parameters to provide the variables when the process instance is created and started. For example, from the RuntimeService:
ProcessInstance startProcessInstanceByKey(String processDefinitionKey, Map<String, Object> variables);
Variables can be added during process execution. For example, (RuntimeService):
void setVariable(String executionId, String variableName, Object value);
void setVariableLocal(String executionId, String variableName, Object value);
void setVariables(String executionId, Map<String, ? extends Object> variables);
void setVariablesLocal(String executionId, Map<String, ? extends Object> variables);
Note that variables can be set local for a given execution (remember, a process instance consists of a tree of executions). The variable will only be visible on that execution and not higher in the tree of executions. This can be useful if data shouldn’t be propagated to the process instance level, or the variable has a new value for a certain path in the process instance (for example, when using parallel paths).
Variables can also be retrieved, as shown below. Note that similar methods exist on the TaskService. This means that tasks, like executions, can have local variables that are 'alive' just for the duration of the task.
Map<String, Object> getVariables(String executionId);
Map<String, Object> getVariablesLocal(String executionId);
Map<String, Object> getVariables(String executionId, Collection<String> variableNames);
Map<String, Object> getVariablesLocal(String executionId, Collection<String> variableNames);
Object getVariable(String executionId, String variableName);
<T> T getVariable(String executionId, String variableName, Class<T> variableClass);
Variables are often used in Java delegates, expressions, execution- or tasklisteners, scripts, and so on. In those constructs, the current execution or task object is available and it can be used for variable setting and/or retrieval. The simplest methods are these:
execution.getVariables();
execution.getVariables(Collection<String> variableNames);
execution.getVariable(String variableName);
execution.setVariables(Map<String, object> variables);
execution.setVariable(String variableName, Object value);
Note that a variant with local is also available for all of the above.
For historical (and backwards-compatibility reasons), when doing any of the calls above, behind the scenes all variables will be fetched from the database. This means that if you have 10 variables, but only get one through getVariable("myVariable"), behind the scenes the other 9 will be fetched and cached. This is not necessarily bad, as subsequent calls will not hit the database again. For example, when your process definition has three sequential service tasks (and thus one database transaction), using one call to fetch all variables in the first service task might be better then fetching the variables needed in each service task separately. Note that this applies both for getting and setting variables.
Of course, when using a lot of variables or simply when you want tight control on the database query and traffic, this is not appropriate. Additional methods have been introduced to give a tighter control on this, by adding in new methods that have an optional parameter that tells the engine whether or not to fetch and cache all variables:
Map<String, Object> getVariables(Collection<String> variableNames, boolean fetchAllVariables);
Object getVariable(String variableName, boolean fetchAllVariables);
void setVariable(String variableName, Object value, boolean fetchAllVariables);
When using true for the parameter fetchAllVariables, the behavior will be exactly as described above: when getting or setting a variable, all other variables will be fetched and cached.
However, when using false as value, a specific query will be used and no other variables will be fetched or cached. Only the value of the variable in question here will be cached for subsequent use.
Transient variables
Transient variables are variables that behave like regular variables, but are not persisted. Typically, transient variables are used for advanced use cases. When in doubt, use a regular process variable.
The following applies for transient variables:
There is no history stored at all for transient variables.
Like regular variables, transient variables are put on the highest parent when set. This means that when setting a variable on an execution, the transient variable is actually stored on the process instance execution. Like regular variables, a local variant of the method exists if the variable is set on the specific execution or task.
A transient variable can only be accessed before the next 'wait state' in the process definition. After that, they are gone. Here, the wait state means the point in the process instance where it is persisted to the data store. Note that an async activity is also a 'wait state' in this definition!
Transient variables can only be set by the setTransientVariable(name, value), but transient variables are also returned when calling getVariable(name) (a getTransientVariable(name) also exists, that only checks the transient variables). The reason for this is to make the writing of expressions easy and existing logic using variables works for both types.
A transient variable shadows a persistent variable with the same name. This means that when both a persistent and transient variable is set on a process instance and getVariable("someVariable") is called, the transient variable value will be returned.
You can set and get transient variables in most places where regular variables are exposed:
On DelegateExecution in JavaDelegate implementations
On DelegateExecution in ExecutionListener implementations and on DelegateTask on TaskListener implementations
In script task via the execution object
When starting a process instance through the runtime service
When completing a task
When calling the runtimeService.trigger method
The methods follow the naming convention of the regular process variables:
void setTransientVariable(String variableName, Object variableValue);
void setTransientVariableLocal(String variableName, Object variableValue);
void setTransientVariables(Map<String, Object> transientVariables);
void setTransientVariablesLocal(Map<String, Object> transientVariables);
Object getTransientVariable(String variableName);
Object getTransientVariableLocal(String variableName);
Map<String, Object> getTransientVariables();
Map<String, Object> getTransientVariablesLocal();
void removeTransientVariable(String variableName);
void removeTransientVariableLocal(String variableName);
The following BPMN diagram shows a typical example:
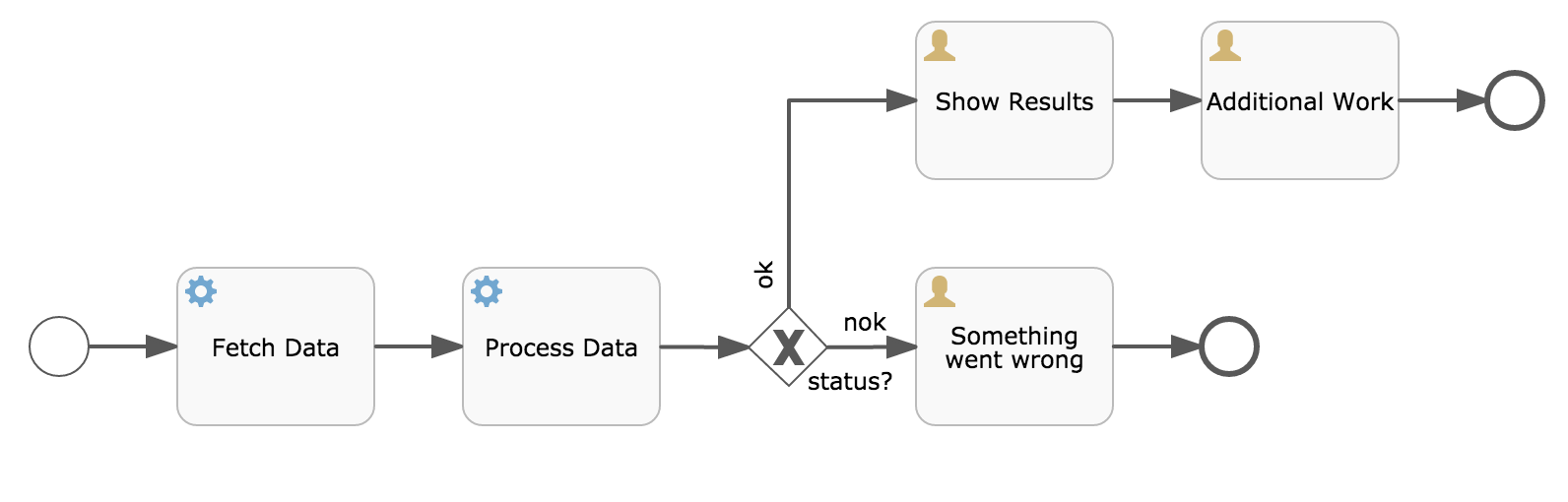
Let’s assume the 'Fetch Data' service task calls some remote service (for example, using REST). Let’s also assume some configuration parameters are needed and need to be provided when starting the process instance. Also, these configuration parameters are not important for historical audit purposes, so we pass them as transient variables:
ProcessInstance processInstance = runtimeService.createProcessInstanceBuilder()
.processDefinitionKey("someKey")
.transientVariable("configParam01", "A")
.transientVariable("configParam02", "B")
.transientVariable("configParam03", "C")
.start();
Note that the transient variables will be available until the user task is reached and persisted to the database. For example, in the 'Additional Work' user task they are no longer available. Also note that if 'Fetch Data' had been asynchronous, they wouldn’t be available after that step either.
The 'Fetch Data' (simplified) could be something like:
public static class FetchDataServiceTask implements JavaDelegate {
public void execute(DelegateExecution execution) {
String configParam01 = (String) execution.getVariable(configParam01);
// ...
RestResponse restResponse = executeRestCall();
execution.setTransientVariable("response", restResponse.getBody());
execution.setTransientVariable("status", restResponse.getStatus());
}
}
The 'Process Data' would get the response transient variable, parse it and store the relevant data in real process variables as we need them later.
The condition on the sequence flow leaving the exclusive gateway are oblivious to whether persistent or transient variables are used (in this case, the status transient variable):
<conditionExpression xsi:type="tFormalExpression">${status == 200}</conditionExpression>
Expressions
Flowable uses UEL for expression-resolving. UEL stands for Unified Expression Language and is part of the EE6 specification (see the EE6 specification for detailed information).
Expressions can be used in, for example, Java Service tasks, Execution Listeners, Task Listeners and Conditional sequence flows. Although there are two types of expressions, value-expression and method-expression, Flowable abstracts this so they can both be used where an expression is expected.
- Value expression: resolves to a value. By default, all process variables are available to use. Also, all spring-beans (if using Spring) are available to use in expressions. Some examples:
${myVar}
${myBean.myProperty}
- Method expression: invokes a method with or without parameters. When invoking a method without parameters, be sure to add empty parentheses after the method-name (as this distinguishes the expression from a value expression). The passed parameters can be literal values or expressions that are resolved themselves. Examples:
${printer.print()}
${myBean.addNewOrder('orderName')}
${myBean.doSomething(myVar, execution)}
Note that these expressions support resolving primitives (including comparing them), beans, lists, arrays and maps.
On top of all process variables, there are a few default objects available that can be used in expressions:
execution: The DelegateExecution holds additional information about the ongoing execution.
task: The DelegateTask holds additional information about the current Task. Note: Only works in expressions evaluated from task listeners.
authenticatedUserId: The id of the user that is currently authenticated. If no user is authenticated, the variable is not available.
variableContainer: The VariableContainer for which the expression is being resolved for.
For more concrete usage and examples, check out Expressions in Spring, Java Service tasks, Execution Listeners, Task Listeners or Conditional sequence flows.
Expression functions
[Experimental] Expression functions have been added in version 6.4.0.
To make working with process variables easier, a set of out-of-the-box functions is available, under the variables namespace.
variables:get(varName): Retrieves the value of a variable. The main difference with writing the variable name directly in the expression is that using this function won’t throw an exception when the variable doesn’t exist. For example ${myVariable == "hello"} would throw an exception if myVariable doesn’t exist, but ${var:get(myVariable) == 'hello'} will just work.
variables:getOrDefault(varName, defaultValue): similar to get, but with the option of providing a default value which is returned when the variable isn’t set or the value is null.
variables:exists(varName): Returns true if the variable has a non-null value.
variables:isEmpty(varName) (alias :empty) : Checks if the variable value is not empty. Depending on the variable type, the behavior is the following:
For String variables, the variable is deemed empty if it’s the empty string.
For java.util.Collection variables, true is returned if the collection has no elements.
For ArrayNode variables, true is returned if there are no elements
In case the variable is null, true is always returned
variables:isNotEmpty(varName) (alias :notEmpty) : the reverse operation of isEmpty.
variables:equals(varName, value) (alias :eq) : checks if a variable is equal to a given value. This is a shorthand function for an expression that would otherwise be written as ${execution.getVariable("varName") != null && execution.getVariable("varName") == value}.
- If the variable value is null, false is returned (unless compared to null).
variables:notEquals(varName, value) (alias :ne) : the reverse comparison of equals.
variables:contains(varName, value1, value2, …): checks if all values provided are contained within a variable. Depending on the variable type, the behavior is the following:
For String variables, the passed values are used as substrings that need to be part of the variable
For java.util.Collection variables, all the passed values need to be an element of the collection (regular contains semantics).
For ArrayNode variables: supports checking if the arraynode contains a JsonNode for the types that are supported as variable type
When the variable value is null, false is returned in all cases. When the variable value is not null, and the instance type is not one of the types above, false will be returned.
variables:containsAny(varName, value1, value2, …) : similar to the contains function, but true will be returned if any (and not all) the passed values is contained in the variable.
variables:base64(varName) : converts a Binary or String variable to a Base64 String
Comparator functions:
variables:lowerThan(varName, value) (alias :lessThan or :lt) : shorthand for ${execution.getVariable("varName") != null && execution.getVariable("varName") < value}
variables:lowerThanOrEquals(varName, value) (alias :lessThanOrEquals or :lte) : similar, but now for < =
variables:greaterThan(varName, value) (alias :gt) : similar, but now for >
variables:greaterThanOrEquals(varName, value) (alias :gte) : similar, but now for > =
The variables namespace is aliased to vars or var. So variables:get(varName) is equivalent to writing vars:get(varName) or var:get(varName). Note that it’s not needed to put quotes around the variable name: var:get(varName) is equivalent to var:get(\'varName') or var:get("varName").
Also note that in none of the functions above the execution needs to be passed into the function (as would be needed when not using a function). The engine will inject the appropriate variable scope when invoking the function. This also means that these functions can be used in exactly the same way when writing expression in CMMN case definitions.
Additionally, it’s possible to register custom functions that can be used in expressions. See the org.flowable.common.engine.api.delegate.FlowableFunctionDelegate interface for more information.
Unit testing
Business processes are an integral part of software projects and they should be tested in the same way normal application logic is tested: with unit tests. Since Flowable is an embeddable Java engine, writing unit tests for business processes is as simple as writing regular unit tests.
Flowable supports JUnit Jupiter styles of unit testing.
In the JUnit Jupiter style one needs to use the org.flowable.engine.test.FlowableTest annotation or register the org.flowable.engine.test.FlowableExtension manually. The FlowableTest annotation is just a meta-annotation and does the registration of the FlowableExtension (i.e., it does @ExtendWith(FlowableExtension.class)). This will make the ProcessEngine and the services available as parameters into the test and lifecycle methods (@BeforeAll, @BeforeEach, @AfterEach, @AfterAll). Before each test the processEngine will be initialized by default with the flowable.cfg.xml resource on the classpath. To specify a different configuration file, the org.flowable.engine.test.ConfigurationResource annotation needs to be used (see second example). Process engines are cached statically over multiple unit tests when the configuration resource is the same.
By using FlowableExtension, you can annotate test methods with org.flowable.engine.test.Deployment. When a test method is annotated with @Deployment, before each test the bpmn files defined in Deployment#resources will be deployed. In case there are no resources defined, a resource file of the form testClassName.testMethod.bpmn20.xml in the same package as the test class, will be deployed. At the end of the test, the deployment will be deleted, including all related process instances, tasks, and so on. See the Deployment class for more information.
Taking all that into account, a JUnit Jupiter test looks as follows:
JUnit Jupiter test with default resource.
@FlowableTest
class MyBusinessProcessTest {
private ProcessEngine processEngine;
private RuntimeService runtimeService;
private TaskService taskService;
@BeforeEach
void setUp(ProcessEngine processEngine) {
this.processEngine = processEngine;
this.runtimeService = processEngine.getRuntimeService();
this.taskService = processEngine.getTaskService();
}
@Test
@Deployment
void testSimpleProcess() {
runtimeService.startProcessInstanceByKey("simpleProcess");
Task task = taskService.createTaskQuery().singleResult();
assertEquals("My Task", task.getName());
taskService.complete(task.getId());
assertEquals(0, runtimeService.createProcessInstanceQuery().count());
}
}
With JUnit Jupiter you can also inject the id of the deployment (with +org.flowable.engine.test.DeploymentId+_) into your test and lifecycle methods.
JUnit Jupiter test with a custom resource file.
@FlowableTest
@ConfigurationResource("flowable.custom.cfg.xml")
class MyBusinessProcessTest {
private ProcessEngine processEngine;
private RuntimeService runtimeService;
private TaskService taskService;
@BeforeEach
void setUp(ProcessEngine processEngine) {
this.processEngine = processEngine;
this.runtimeService = processEngine.getRuntimeService();
this.taskService = processEngine.getTaskService();
}
@Test
@Deployment
void testSimpleProcess() {
runtimeService.startProcessInstanceByKey("simpleProcess");
Task task = taskService.createTaskQuery().singleResult();
assertEquals("My Task", task.getName());
taskService.complete(task.getId());
assertEquals(0, runtimeService.createProcessInstanceQuery().count());
}
}
Debugging unit tests
When using the in-memory H2 database for unit tests, the following instructions allow you to easily inspect the data in the Flowable database during a debugging session. The screenshots here are taken in Eclipse, but the mechanism should be similar for other IDEs.
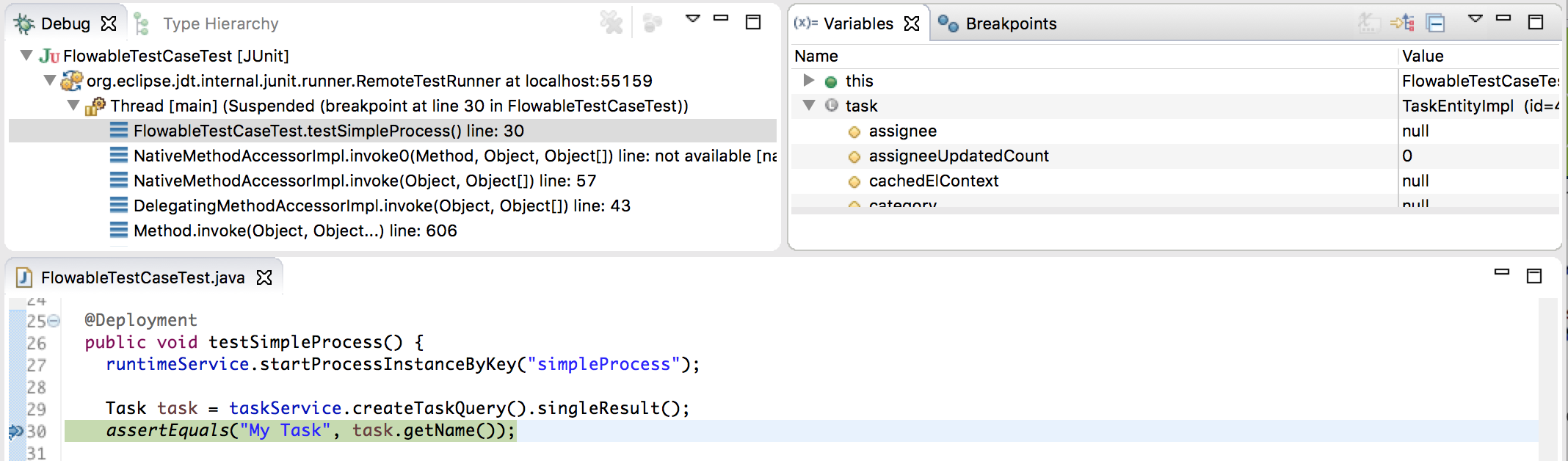
Suppose we have put a breakpoint somewhere in our unit test (in Eclipse this is done by double-clicking in the left border next to the code):

If we now run the unit test in debug mode (right-click in test class, select 'Run as' and then 'JUnit test'), the test execution halts at our breakpoint, where we can now inspect the variables of our test as shown in the right upper panel.
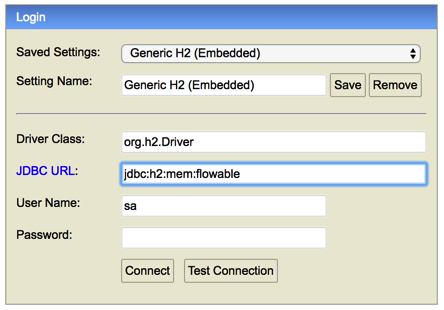
To inspect the Flowable data, open up the 'Display' window (if this window isn’t there, open Window→Show View→Other and select Display.) and type (code completion is available) org.h2.tools.Server.createWebServer("-web").start()
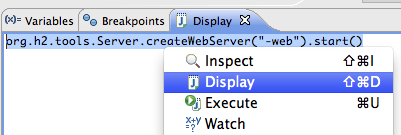
Select the line you’ve just typed and right-click on it. Now select 'Display' (or execute the shortcut instead of right-clicking)

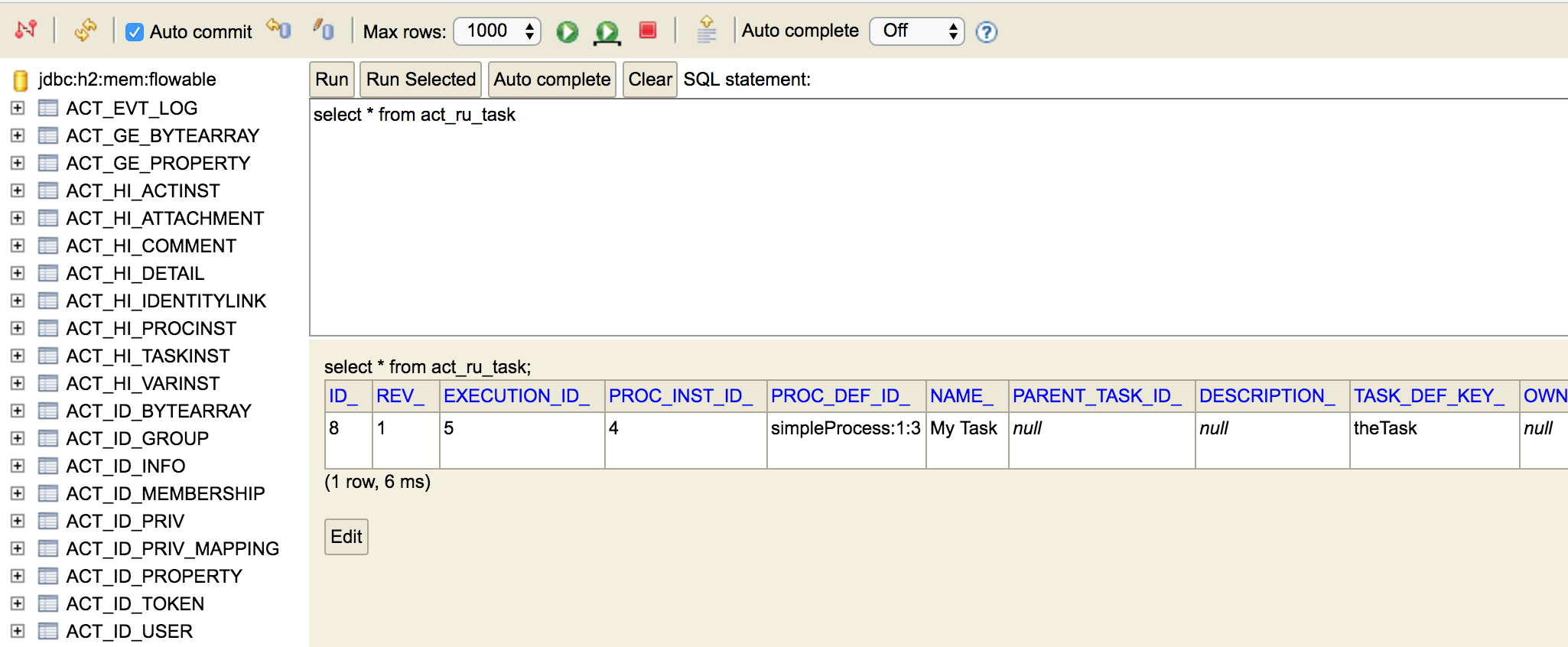
Now open up a browser and go to http://localhost:8082, and fill in the JDBC URL to the in-memory database (by default this is jdbc:h2:mem:flowable), and hit the connect button.
You can now see the Flowable data and use it to understand how and why your unit test is executing your process in a certain way.
The process engine in a web application
The ProcessEngine is a thread-safe class and can easily be shared among multiple threads. In a web application, this means it is possible to create the process engine once when the container boots and shut down the engine when the container goes down.
The following code snippet shows how you can write a simple ServletContextListener to initialize and destroy process engines in a plain Servlet environment:
public class ProcessEnginesServletContextListener implements ServletContextListener {
public void contextInitialized(ServletContextEvent servletContextEvent) {
ProcessEngines.init();
}
public void contextDestroyed(ServletContextEvent servletContextEvent) {
ProcessEngines.destroy();
}
}
The contextInitialized method will delegate to ProcessEngines.init(). That will look for flowable.cfg.xml resource files on the classpath, and create a ProcessEngine for the given configurations (for example, multiple JARs with a configuration file). If you have multiple such resource files on the classpath, make sure they all have different names. When the process engine is needed, it can be fetched using:
ProcessEngines.getDefaultProcessEngine()
or
ProcessEngines.getProcessEngine("myName");
Of course, it is also possible to use any of the variants of creating a process engine, as described in the configuration section.
The contextDestroyed method of the context-listener delegates to ProcessEngines.destroy(). That will properly close all initialized process engines.